Хи квадрат распределение случайной величины. Распределение ХИ-квадрат. Распределения математической статистики в MS EXCEL. Функции MS EXCEL, использующие ХИ2-распределение
Пусть U 1 , U 2 , ..,U k - независимые стандартные нормальные величины. Распределение случайной величины K = U 1 2 +U 2 2 + .. + U k 2 называется распределением «хи-квадрат» с k степенями свободы (пишут K~χ 2 (k)). Это унимодальное распределение с положительной асимметрией и следующими характеристиками: мода M=k-2 математическое ожидание m=k дисперсия D=2k (рис.). При достаточно большом значении параметра k распределение χ 2 (k) имеет приближенно нормальное распределение с параметрами
При решении задач математической статистики используются критические точки χ 2 (k) зависящие от заданной вероятности α и числа степеней свободы k
(приложение 2). Критическая точка Χ 2 кр =Χ 2 (k; α) является границей области, правее которой лежит 100- α % площади под кривой плотности распределения. Вероятность того, что значение случайной величины K~χ 2 (k)при испытаниях попадет правее точки χ 2 (k) не превышает α P(K≥χ 2 kp)≤ α). Например, для случайной величины K~χ 2 (20) зададим вероятность α=0.05. По таблице критических точек распределения «хи-квадрат» (таблицы) находим χ 2 kp = χ 2 (20;0.05)=31.4. Значит, вероятность этой случайной величине K
принять значение, большее 31.4, меньше 0.05 (рис.).

Рис. График плотности распределения χ 2 (k)при различных значениях числа степеней свободы k
Критические точки χ 2 (k) используются в следующих калькуляторах:
- Проверка наличия мультиколлинеарности (о мультиколлинеарности).
Поэтому для проверки направления связи выбирается корреляционный анализ, в частности проверка гипотезы при помощи коэффициента корреляции Пирсона с дальнейшей проверкой на достоверность при помощи t-критерия.
Для любого значения уровня значимости α Χ 2 можно найти с помощью функции MS Excel : =ХИ2ОБР(α;степеней свободы)
| n-1 | .995 | .990 | .975 | .950 | .900 | .750 | .500 | .250 | .100 | .050 | .025 | .010 | .005 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.00004 | 0.00016 | 0.00098 | 0.00393 | 0.01579 | 0.10153 | 0.45494 | 1.32330 | 2.70554 | 3.84146 | 5.02389 | 6.63490 | 7.87944 |
| 2 | 0.01003 | 0.02010 | 0.05064 | 0.10259 | 0.21072 | 0.57536 | 1.38629 | 2.77259 | 4.60517 | 5.99146 | 7.37776 | 9.21034 | 10.59663 |
| 3 | 0.07172 | 0.11483 | 0.21580 | 0.35185 | 0.58437 | 1.21253 | 2.36597 | 4.10834 | 6.25139 | 7.81473 | 9.34840 | 11.34487 | 12.83816 |
| 4 | 0.20699 | 0.29711 | 0.48442 | 0.71072 | 1.06362 | 1.92256 | 3.35669 | 5.38527 | 7.77944 | 9.48773 | 11.14329 | 13.27670 | 14.86026 |
| 5 | 0.41174 | 0.55430 | 0.83121 | 1.14548 | 1.61031 | 2.67460 | 4.35146 | 6.62568 | 9.23636 | 11.07050 | 12.83250 | 15.08627 | 16.74960 |
| 6 | 0.67573 | 0.87209 | 1.23734 | 1.63538 | 2.20413 | 3.45460 | 5.34812 | 7.84080 | 10.64464 | 12.59159 | 14.44938 | 16.81189 | 18.54758 |
| 7 | 0.98926 | 1.23904 | 1.68987 | 2.16735 | 2.83311 | 4.25485 | 6.34581 | 9.03715 | 12.01704 | 14.06714 | 16.01276 | 18.47531 | 20.27774 |
| 8 | 1.34441 | 1.64650 | 2.17973 | 2.73264 | 3.48954 | 5.07064 | 7.34412 | 10.21885 | 13.36157 | 15.50731 | 17.53455 | 20.09024 | 21.95495 |
| 9 | 1.73493 | 2.08790 | 2.70039 | 3.32511 | 4.16816 | 5.89883 | 8.34283 | 11.38875 | 14.68366 | 16.91898 | 19.02277 | 21.66599 | 23.58935 |
| 10 | 2.15586 | 2.55821 | 3.24697 | 3.94030 | 4.86518 | 6.73720 | 9.34182 | 12.54886 | 15.98718 | 18.30704 | 20.48318 | 23.20925 | 25.18818 |
| 11 | 2.60322 | 3.05348 | 3.81575 | 4.57481 | 5.57778 | 7.58414 | 10.34100 | 13.70069 | 17.27501 | 19.67514 | 21.92005 | 24.72497 | 26.75685 |
| 12 | 3.07382 | 3.57057 | 4.40379 | 5.22603 | 6.30380 | 8.43842 | 11.34032 | 14.84540 | 18.54935 | 21.02607 | 23.33666 | 26.21697 | 28.29952 |
| 13 | 3.56503 | 4.10692 | 5.00875 | 5.89186 | 7.04150 | 9.29907 | 12.33976 | 15.98391 | 19.81193 | 22.36203 | 24.73560 | 27.68825 | 29.81947 |
| 14 | 4.07467 | 4.66043 | 5.62873 | 6.57063 | 7.78953 | 10.16531 | 13.33927 | 17.11693 | 21.06414 | 23.68479 | 26.11895 | 29.14124 | 31.31935 |
| 15 | 4.60092 | 5.22935 | 6.26214 | 7.26094 | 8.54676 | 11.03654 | 14.33886 | 18.24509 | 22.30713 | 24.99579 | 27.48839 | 30.57791 | 32.80132 |
| 16 | 5.14221 | 5.81221 | 6.90766 | 7.96165 | 9.31224 | 11.91222 | 15.33850 | 19.36886 | 23.54183 | 26.29623 | 28.84535 | 31.99993 | 34.26719 |
| 17 | 5.69722 | 6.40776 | 7.56419 | 8.67176 | 10.08519 | 12.79193 | 16.33818 | 20.48868 | 24.76904 | 27.58711 | 30.19101 | 33.40866 | 35.71847 |
| 18 | 6.26480 | 7.01491 | 8.23075 | 9.39046 | 10.86494 | 13.67529 | 17.33790 | 21.60489 | 25.98942 | 28.86930 | 31.52638 | 34.80531 | 37.15645 |
| 19 | 6.84397 | 7.63273 | 8.90652 | 10.11701 | 11.65091 | 14.56200 | 18.33765 | 22.71781 | 27.20357 | 30.14353 | 32.85233 | 36.19087 | 38.58226 |
| 20 | 7.43384 | 8.26040 | 9.59078 | 10.85081 | 12.44261 | 15.45177 | 19.33743 | 23.82769 | 28.41198 | 31.41043 | 34.16961 | 37.56623 | 39.99685 |
| 21 | 8.03365 | 8.89720 | 10.28290 | 11.59131 | 13.23960 | 16.34438 | 20.33723 | 24.93478 | 29.61509 | 32.67057 | 35.47888 | 38.93217 | 41.40106 |
| 22 | 8.64272 | 9.54249 | 10.98232 | 12.33801 | 14.04149 | 17.23962 | 21.33704 | 26.03927 | 30.81328 | 33.92444 | 36.78071 | 40.28936 | 42.79565 |
| 23 | 9.26042 | 10.19572 | 11.68855 | 13.09051 | 14.84796 | 18.13730 | 22.33688 | 27.14134 | 32.00690 | 35.17246 | 38.07563 | 41.63840 | 44.18128 |
| 24 | 9.88623 | 10.85636 | 12.40115 | 13.84843 | 15.65868 | 19.03725 | 23.33673 | 28.24115 | 33.19624 | 36.41503 | 39.36408 | 42.97982 | 45.55851 |
| 25 | 10.51965 | 11.52398 | 13.11972 | 14.61141 | 16.47341 | 19.93934 | 24.33659 | 29.33885 | 34.38159 | 37.65248 | 40.64647 | 44.31410 | 46.92789 |
| 26 | 11.16024 | 12.19815 | 13.84390 | 15.37916 | 17.29188 | 20.84343 | 25.33646 | 30.43457 | 35.56317 | 38.88514 | 41.92317 | 45.64168 | 48.28988 |
| 27 | 11.80759 | 12.87850 | 14.57338 | 16.15140 | 18.11390 | 21.74940 | 26.33634 | 31.52841 | 36.74122 | 40.11327 | 43.19451 | 46.96294 | 49.64492 |
| 28 | 12.46134 | 13.56471 | 15.30786 | 16.92788 | 18.93924 | 22.65716 | 27.33623 | 32.62049 | 37.91592 | 41.33714 | 44.46079 | 48.27824 | 50.99338 |
| 29 | 13.12115 | 14.25645 | 16.04707 | 17.70837 | 19.76774 | 23.56659 | 28.33613 | 33.71091 | 39.08747 | 42.55697 | 45.72229 | 49.58788 | 52.33562 |
| 30 | 13.78672 | 14.95346 | 16.79077 | 18.49266 | 20.59923 | 24.47761 | 29.33603 | 34.79974 | 40.25602 | 43.77297 | 46.97924 | 50.89218 | 53.67196 |
| Число степеней свободы k | Уровень значимости a | |||||
| 0,01 | 0,025 | 0.05 | 0,95 | 0,975 | 0.99 | |
| 1 | 6.6 | 5.0 | 3.8 | 0.0039 | 0.00098 | 0.00016 |
| 2 | 9.2 | 7.4 | 6.0 | 0.103 | 0.051 | 0.020 |
| 3 | 11.3 | 9.4 | 7.8 | 0.352 | 0.216 | 0.115 |
| 4 | 13.3 | 11.1 | 9.5 | 0.711 | 0.484 | 0.297 |
| 5 | 15.1 | 12.8 | 11.1 | 1.15 | 0.831 | 0.554 |
| 6 | 16.8 | 14.4 | 12.6 | 1.64 | 1.24 | 0.872 |
| 7 | 18.5 | 16.0 | 14.1 | 2.17 | 1.69 | 1.24 |
| 8 | 20.1 | 17.5 | 15.5 | 2.73 | 2.18 | 1.65 |
| 9 | 21.7 | 19.0 | 16.9 | 3.33 | 2.70 | 2.09 |
| 10 | 23.2 | 20.5 | 18.3 | 3.94 | 3.25 | 2.56 |
| 11 | 24.7 | 21.9 | 19.7 | 4.57 | 3.82 | 3.05 |
| 12 | 26.2 | 23.3 | 21 .0 | 5.23 | 4.40 | 3.57 |
| 13 | 27.7 | 24.7 | 22.4 | 5.89 | 5.01 | 4.11 |
| 14 | 29.1 | 26.1 | 23.7 | 6.57 | 5.63 | 4.66 |
| 15 | 30.6 | 27.5 | 25.0 | 7.26 | 6.26 | 5.23 |
| 16 | 32.0 | 28.8 | 26.3 | 7.96 | 6.91 | 5.81 |
| 17 | 33.4 | 30.2 | 27.6 | 8.67 | 7.56 | 6.41 |
| 18 | 34.8 | 31.5 | 28.9 | 9.39 | 8.23 | 7.01 |
| 19 | 36.2 | 32.9 | 30.1 | 10.1 | 8.91 | 7.63 |
| 20 | 37.6 | 34.2 | 31.4 | 10.9 | 9.59 | 8.26 |
| 21 | 38.9 | 35.5 | 32.7 | 11.6 | 10.3 | 8.90 |
| 22 | 40.3 | 36.8 | 33.9 | 12.3 | 11.0 | 9.54 |
| 23 | 41.6 | 38.1 | 35.2 | 13.1 | 11.7 | 10.2 |
| 24 | 43.0 | 39.4 | 36.4 | 13.8 | 12.4 | 10.9 |
| 25 | 44.3 | 40.6 | 37.7 | 14.6 | 13.1 | 11.5 |
| 26 | 45.6 | 41.9 | 38.9 | 15.4 | 13.8 | 12.2 |
| 27 | 47.0 | 43.2 | 40.1 | 16.2 | 14.6 | 12.9 |
| 28 | 48.3 | 44.5 | 41.3 | 16.9 | 15.3 | 13.6 |
| 29 | 49.6 | 45.7 | 42.6 | 17.7 | 16.0 | 14.3 |
| 30 | 50.9 | 47.0 | 43.8 | 18.5 | 16.8 | 15.0 |
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию города Иркутска
Байкальский государственный университет экономики и права
Кафедра Информатики и Кибернетики
Распределение "хи-квадрат" и его применение
Колмыкова Анна Андреевна
студентка 2 курса
группы ИС-09-1
Иркутск 2010
Введение
1. Распределение "хи-квадрат"
Приложение
Заключение
Список используемой литературы
Введение
Как подходы, идеи и результаты теории вероятностей используются в нашей жизни?
Базой является вероятностная модель реального явления или процесса, т.е. математическая модель, в которой объективные соотношения выражены в терминах теории вероятностей. Вероятности используются, прежде всего, для описания неопределенностей, которые необходимо учитывать при принятии решений. Имеются в виду, как нежелательные возможности (риски), так и привлекательные ("счастливый случай"). Иногда случайность вносится в ситуацию сознательно, например, при жеребьевке, случайном отборе единиц для контроля, проведении лотерей или опросов потребителей.
Теория вероятностей позволяет по одним вероятностям рассчитать другие, интересующие исследователя.
Вероятностная модель явления или процесса является фундаментом математической статистики. Используются два параллельных ряда понятий – относящиеся к теории (вероятностной модели) и относящиеся к практике (выборке результатов наблюдений). Например, теоретической вероятности соответствует частота, найденная по выборке. Математическому ожиданию (теоретический ряд) соответствует выборочное среднее арифметическое (практический ряд). Как правило, выборочные характеристики являются оценками теоретических. При этом величины, относящиеся к теоретическому ряду, "находятся в головах исследователей", относятся к миру идей (по древнегреческому философу Платону), недоступны для непосредственного измерения. Исследователи располагают лишь выборочными данными, с помощью которых они стараются установить интересующие их свойства теоретической вероятностной модели.
Зачем же нужна вероятностная модель? Дело в том, что только с ее помощью можно перенести свойства, установленные по результатам анализа конкретной выборки, на другие выборки, а также на всю так называемую генеральную совокупность. Термин "генеральная совокупность" используется, когда речь идет о большой, но конечной совокупности изучаемых единиц. Например, о совокупности всех жителей России или совокупности всех потребителей растворимого кофе в Москве. Цель маркетинговых или социологических опросов состоит в том, чтобы утверждения, полученные по выборке из сотен или тысяч человек, перенести на генеральные совокупности в несколько миллионов человек. При контроле качества в роли генеральной совокупности выступает партия продукции.
Чтобы перенести выводы с выборки на более обширную совокупность, необходимы те или иные предположения о связи выборочных характеристик с характеристиками этой более обширной совокупности. Эти предположения основаны на соответствующей вероятностной модели.
Конечно, можно обрабатывать выборочные данные, не используя ту или иную вероятностную модель. Например, можно рассчитывать выборочное среднее арифметическое, подсчитывать частоту выполнения тех или иных условий и т.п. Однако результаты расчетов будут относиться только к конкретной выборке, перенос полученных с их помощью выводов на какую-либо иную совокупность некорректен. Иногда подобную деятельность называют "анализ данных". По сравнению с вероятностно-статистическими методами анализ данных имеет ограниченную познавательную ценность.
Итак, использование вероятностных моделей на основе оценивания и проверки гипотез с помощью выборочных характеристик – вот суть вероятностно-статистических методов принятия решений.
Распределение "хи-квадрат"
С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных. Это распределения Пирсона ("хи – квадрат"), Стьюдента и Фишера.
Мы остановимся на распределении
("хи – квадрат"). Впервые это распределение было исследовано астрономом Ф.Хельмертом в 1876 году. В связи с гауссовской теорией ошибок он исследовал суммы квадратов n независимых стандартно нормально распределенных случайных величин. Позднее Карл Пирсон (Karl Pearson) дал имя данной функции распределения "хи – квадрат". И сейчас распределение носит его имя.Благодаря тесной связи с нормальным распределением, χ2-распределение играет важную роль в теории вероятностей и математической статистике. χ2-распределение, и многие другие распределения, которые определяются посредством χ2-распределения (например - распределение Стьюдента), описывают выборочные распределения различных функций от нормально распределенных результатов наблюдений и используются для построения доверительных интервалов и статистических критериев.
Распределение Пирсона
(хи - квадрат) – распределение случайной величины где X1, X2,…, Xn - нормальные независимые случайные величины, причем математическое ожидание каждой из них равно нулю, а среднее квадратическое отклонение - единице.Сумма квадратов
распределена по закону
("хи – квадрат").При этом число слагаемых, т.е. n, называется "числом степеней свободы" распределения хи – квадрат. C увеличением числа степеней свободы распределение медленно приближается к нормальному.
Плотность этого распределения
Итак, распределение χ2 зависит от одного параметра n – числа степеней свободы.
Функция распределения χ2 имеет вид:
если χ2≥0. (2.7.)
На Рисунок 1 изображен график плотности вероятности и функции χ2 – распределения для разных степеней свободы.
Рисунок 1 Зависимость плотности вероятности φ (x) в распределении χ2 (хи – квадрат) при разном числе степеней свободы.
Моменты распределения "хи-квадрат":
Распределение "хи-квадрат" используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости, прежде всего для качественных (категоризованных) переменных, принимающих конечное число значений, и во многих других задачах статистического анализа данных.
2. "Хи-квадрат" в задачах статистического анализа данных
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью.
Современный этап развития статистических методов можно отсчитывать с 1900 г., когда англичанин К. Пирсон основал журнал "Biometrika". Первая треть ХХ в. прошла под знаком параметрической статистики. Изучались методы, основанные на анализе данных из параметрических семейств распределений, описываемых кривыми семейства Пирсона. Наиболее популярным было нормальное распределение. Для проверки гипотез использовались критерии Пирсона, Стьюдента, Фишера. Были предложены метод максимального правдоподобия, дисперсионный анализ, сформулированы основные идеи планирования эксперимента.
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна
где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Хи-квадрат критерий – универсальный метод проверки согласия результатов эксперимента и используемой статистической модели.
Расстояние Пирсона X 2
Пятницкий А.М.
Российский Государственный Медицинский Университет
В 1900 году Карл Пирсон предложил простой, универсальный и эффективный способ проверки согласия между предсказаниями модели и опытными данными. Предложенный им “хи-квадрат критерий” – это самый важный и наиболее часто используемыйстатистический критерий. Большинство задач, связанных с оценкой неизвестных параметров модели и проверки согласия модели и опытных данных, можно решить с его помощью.
Пусть имеется априорная (“до опытная”) модельизучаемого объекта или процесса (в статистике говорят о “нулевой гипотезе” H 0), и результаты опыта с этим объектом. Следует решить, адекватна ли модель (соответствует ли она реальности)? Не противоречат ли результаты опыта нашим представлениям о том, как устроена реальность, или иными словами - следует ли отвергнуть H 0 ? Часто эту задачу можно свести к сравнению наблюдаемых (O i = Observed )и ожидаемых согласно модели (E i =Expected ) средних частот появления неких событий. Считается, что наблюдаемые частоты получены в серии N независимых (!) наблюдений, производимых в постоянных (!) условиях. В результате каждого наблюдения регистрируется одно из M событий. Эти события не могут происходить одновременно (попарно несовместны) и одно из них обязательно происходит (их объединение образует достоверное событие). Совокупность всех наблюдений сводится к таблице (вектору) частот {O i }=(O 1 ,… O M ), которая полностью описывает результаты опыта. Значение O 2 =4 означает, что событие номер 2 произошло 4 раза. Сумма частот O 1 +… O M =N . Важно различать два случая: N – фиксировано, неслучайно, N – случайная величина. При фиксированном общем числе опытов N частоты имеют полиномиальное распределение. Поясним эту общую схему простым примером.
Применение хи-квадрат критерия для проверки простых гипотез.
Пусть модель (нулевая гипотеза H 0) заключается в том, что игральная кость является правильной - все грани выпадают одинаково часто с вероятностью p i =1/6, i =, M=6. Проведен опыт, который состоял в том, что кость бросили 60 раз (провели N =60 независимых испытаний). Согласно модели мы ожидаем, что все наблюдаемые частоты O i появления 1,2,... 6 очков должны быть близки к своим средним значениям E i =Np i =60∙(1/6)=10. Согласно H 0 вектор средних частот {E i }={Np i }=(10, 10, 10, 10, 10, 10). (Гипотезы, в которых средние частоты полностью известны до начала опыта, называются простыми.) Если бы наблюдаемый вектор {O i } был равен (34,0,0,0,0,26) , то сразу ясно, что модель неверна – кость не может быть правильной, так как60 раз выпадали только 1 и 6. Вероятность такого события для правильной игральной кости ничтожна: P = (2/6) 60 =2.4*10 -29 . Однако появление столь явных расхождений между моделью и опытом исключение. Пусть вектор наблюдаемых частот {O i } равен (5, 15, 6, 14, 4, 16). Согласуется ли это с H 0 ? Итак, нам надо сравнить два вектора частот {E i } и {O i }. При этом вектор ожидаемых частот {E i } не случаен, а вектор наблюдаемых {O i } случаен – при следующем опыте (в новой серии из 60 бросков) он окажется другим. Полезно ввести геометрическую интерпретацию задачи и считать, что в пространстве частот (в данном случае 6 мерном) даны две точки с координатами(5, 15, 6, 14, 4, 16) и (10, 10, 10, 10, 10, 10). Достаточно ли далеко они удалены друг от друга, чтобы счесть это несовместным сH 0 ? Иными словами нам надо:
- научиться измерять расстояния между частотами (точками пространства частот),
- иметь критерий того, какое расстояние следует считать слишком (“неправдоподобно”) большим, то есть несовместным с H 0 .
Квадрат обычного евклидова расстояниябыл бы равен:
X 2 Euclid = S (O i -E i) 2 = (5-10) 2 +(15-10) 2 + (6-10) 2 +(14-10) 2 +(4-10) 2 +(16-10) 2
При этом поверхности X 2 Euclid = const всегда являются сферами, если мы фиксируем значения E i и меняем O i . Карл Пирсон заметил, что использовать евклидово расстояние в пространстве частот не следует. Так, неправильно считать, что точки (O =1030 и E =1000) и (O =40 и E =10) находятся на равном расстоянии друг от друга, хотя в обоих случаях разность O -E =30. Ведь чем больше ожидаемая частота, тем большие отклонения от нее следует считать возможными. Поэтому точки (O =1030 и E =1000) должны считаться “близкими”, а точки (O =40 и E =10) “далекими” друг от друга. Можно показать, что если верна гипотеза H 0 , то флуктуации частоты O i относительно E i имеют величину порядка квадратного корня(!) из E i . Поэтому Пирсон предложил при вычислении расстояния возводить в квадраты не разности (O i -E i ), а нормированные разности (O i -E i )/E i 1/2 . Итак, вот формула, по которой вычисляется расстояние Пирсона (фактически это квадрат расстояния):
X 2 Pearson = S ((O i -E i )/E i 1/2) 2 =S (O i -E i ) 2 /E i
В нашем примере:
X 2 Pearson = (5-10) 2 /10+(15-10) 2 /10 +(6-10) 2 /10+(14-10) 2 /10+(4-10) 2 /10+(16-10) 2 /10=15.4
Для правильной игральной кости все ожидаемые частоты E i одинаковы, но обычно они различны, поэтому поверхности, на которых расстояние Пирсона постоянно (X 2 Pearson =const) оказываются уже эллипсоидами, а не сферами.
Теперь после того, как выбрана формула для подсчета расстояний, необходимо выяснить, какие расстояния следует считать “не слишком большими” (согласующимися с H 0).Так, например, что можно сказать по поводу вычисленного нами расстояния 15.4? В каком проценте случаев (или с какой вероятностью), проводя опыты с правильной игральной костью, мы получали бы расстояние большее, чем 15.4? Если этот процент будет мал (<0.05), то H 0 надо отвергнуть. Иными словами требуется найти распределение длярасстояния Пирсона. Если все ожидаемые частоты E i не слишком малы (≥5), и верна H 0 , то нормированные разности (O i - E i )/E i 1/2 приближенно эквивалентны стандартным гауссовским случайным величинам: (O i - E i )/E i 1/2 ≈N (0,1). Это, например, означает, что в 95% случаев| (O i - E i )/E i 1/2 | < 1.96 ≈ 2 (правило “двух сигм”).
Пояснение . Число измерений O i , попадающих в ячейку таблицы с номером i , имеет биномиальное распределение с параметрами: m =Np i =E i ,σ =(Np i (1-p i )) 1/2 , где N - число измерений (N »1), p i – вероятность для одного измерения попасть в данную ячейку (напомним, что измерения независимы и производятся в постоянных условиях). Если p i мало, то: σ≈(Np i ) 1/2 =E i и биномиальное распределение близко к пуассоновскому, в котором среднее число наблюдений E i =λ, а среднее квадратичное отклонение σ=λ 1/2 = E i 1/2 . Для λ≥5пуассоновскоераспределение близко к нормальному N (m =E i =λ, σ=E i 1/2 =λ 1/2), а нормированная величина (O i - E i )/E i 1/2 ≈ N (0,1).
Пирсон определил случайную величину χ 2 n – “хи-квадрат с n степенями свободы”, как сумму квадратов n независимых стандартных нормальных с.в.:
χ 2 n = T 1 2 + T 2 2 + …+ T n 2 , гдевсе T i = N(0,1) - н. о. р. с. в.
Попытаемся наглядно понять смысл этой важнейшей в статистике случайной величины. Для этого на плоскости (при n
=2) или в пространстве (при n
=3) представим облако точек, координаты которых независимы и имеют стандартное нормальное распределениеf
T
(x
) ~exp
(-x
2 /2). На плоскости согласно правилу “двух сигм”, которое независимо применяется к обеим координатам, 90% (0.95*0.95≈0.90) точек заключены внутри квадрата(-2 f χ 2 2 (a) =
Сexp(-a/2) = 0.5exp(-a/2).
При достаточно большом числе степеней свободы n
(n
>30) хи-квадрат распределение приближается к нормальному: N
(m
= n
; σ = (2n
) ½). Это следствие “центральной предельной теоремы”: сумма одинаково распределенных величин имеющих конечную дисперсию приближается к нормальному закону с ростом числа слагаемых. Практически надо запомнить, что средний квадрат расстояния равен m
(χ
2 n
)=n
, а его дисперсия σ 2 (χ
2 n
)=2n
. Отсюда легко заключить какие значения хи-квадрат следует считать слишком малыми и слишком большими:большая часть распределения заключена в пределахот n
-2∙(2n
) ½ до n
+2∙(2n
) ½ . Итак, расстояния Пирсона существенно превышающие n
+2∙ (2n
) ½ , следует считать неправдоподобно большими (не согласующимися с H
0) . Если результат близок к n
+2∙(2n
) ½ , то следует воспользоваться таблицами, в которых можно точно узнать в какой доле случаев могут появляться такие и большие значения хи-квадрат. Важно знать, как правильно выбирать значение числа степеней свободы (number degrees of freedom , сокращенно n
.d
.f
.). Казалось естественным считать, что n
просто равно числу разрядов: n
=M
. В своей статье Пирсон так и предположил. В примере с игральной костью это означало бы, что n
=6. Однако спустя несколько лет было показано, что Пирсон ошибся. Число степеней свободы всегда меньше числа разрядов, если между случайными величинами O i
есть связи. Для примера с игральной костью сумма O i
равна 60, и независимо менять можно лишь 5 частот, так что правильное значение n
=6-1=5. Для этого значения n
получаем n
+2∙(2n
) ½ =5+2∙(10) ½ =11.3. Так как15.4>11.3, то гипотезу H
0 - игральная кость правильная, следует отвергнуть. После выяснения ошибки, существовавшие таблицы χ
2 пришлось дополнить, так как исходно в них не было случая n
=1, так как наименьшее число разрядов =2. Теперь же оказалось, что могут быть случаи, когда расстояние Пирсона имеет распределение χ
2 n
=1 . Пример
. При 100 бросаниях монеты число гербов равно O
1 = 65, а решек O
2 = 35. Число разрядов M
=2. Если монета симметрична, то ожидаемые частотыE
1 =50, E
2 =50. X 2 Pearson =
S
(O i -E i) 2 /E i = (65-50) 2 /50 + (35-50) 2 /50 = 2*225/50 = 9.
Полученное значение следует сравнивать с теми, которые может принимать случайная величина χ
2 n
=1 , определенная как квадрат стандартной нормальной величины χ
2 n
=1 =T
1 2 ≥ 9 ó
T
1 ≥3 или T
1 ≤-3. Вероятность такого события весьма мала P
(χ
2 n
=1 ≥9) = 0.006. Поэтому монету нельзя считать симметричной: H
0 следует отвергнуть. То, что число степеней свободы не может быть равно числу разрядов видно из того, что сумма наблюдаемых частот всегда равна сумме ожидаемых, например O
1 +O
2 =65+35 = E
1 +E
2 =50+50=100. Поэтому случайные точки с координатами O
1 и O
2 располагаются на прямой: O
1 +O
2 =E
1 +E
2 =100 и расстояние до центра оказывается меньше, чем, если бы этого ограничения не было, и они располагались на всей плоскости. Действительно для двух независимые случайных величин с математическими ожиданиями E
1 =50, E
2 =50, сумма их реализаций не должна быть всегда равной 100 – допустимыми были бы, например, значения O
1 =60, O
2 =55. Пояснение
. Сравним результат, критерия Пирсона при M
=2 с тем, что дает формула Муавра Лапласа при оценке случайных колебаний частоты появления события ν
=K
/N
имеющего вероятность p
в серии N
независимых испытаний Бернулли (K
-число успехов): χ
2 n
=1 =S
(O i
-E i
) 2 /E i
= (O
1 -E
1) 2 /E
1 + (O
2 -E
2) 2 /E
2 = (Nν
-Np
) 2 /(Np
) + (N
(1-ν
)-N
(1-p
)) 2 /(N
(1-p
))= =(Nν-Np) 2 (1/p + 1/(1-p))/N=(Nν-Np) 2 /(Np(1-p))=((K-Np)/(Npq) ½) 2 = T 2
Величина T
=(K
-Np
)/(Npq
) ½ = (K
-m
(K
))/σ(K
) ≈N
(0,1) при σ(K
)=(Npq
) ½ ≥3. Мы видим, что в этом случае результат Пирсона в точности совпадает с тем, что дает применение нормальной аппроксимации для биномиального распределения. До сих пор мы рассматривали простые гипотезы, для которых ожидаемые средние частоты E i
полностью известны заранее. О том, как правильно выбирать число степеней свободы для сложных гипотез см. ниже. В примерах с правильной игральной костью и монетой ожидаемые частоты можно было определить до(!) проведения опыта. Подобные гипотезы называются “простыми”. На практике чаще встречаются “сложные гипотезы”. При этом для того, чтобы найти ожидаемые частоты E i
надо предварительно оценить одну или несколько величин (параметры модели), и сделать это можно только, воспользовавшись данными опыта. В результате для “сложных гипотез” ожидаемые частоты E i
оказываются зависящими от наблюдаемых частот O i
и потому сами становятся случайными величинами, меняющимися в зависимости от результатов опыта. В процессе подбора параметров расстояние Пирсона уменьшается – параметры подбираются так, чтобы улучшить согласие модели и опыта. Поэтому число степеней свободы должно уменьшаться. Как оценить параметры модели? Есть много разных способов оценки – “метод максимального правдоподобия”, “метод моментов”, “метод подстановки”. Однако можно не привлекать никаких дополнительных средств и найти оценки параметров минимизируя расстояние Пирсона. В докомпьютерную эпоху такой подход использовался редко: приручных расчетах он неудобен и, как правило, не поддается аналитическому решению. При расчетах на компьютере численная минимизация обычно легко осуществляется, а преимуществом такого способа является его универсальность. Итак, согласно “методу минимизации хи-квадрат”, мы подбираем значения неизвестных параметров так, чтобы расстояние Пирсона стало наименьшим. (Кстати, изучая изменения этого расстояния при небольших смещениях относительно найденного минимума можно оценить меру точности оценки: построить доверительные интервалы.) После того как параметры и само это минимальное расстояние найдено опять требуется ответить на вопрос достаточно ли оно мало. Общая последовательность действий такова:
P
(χ
2 n
> χ
2 крит)=1-α, где α – “уровень значимости” или ”размер критерия” или “величина ошибки первого рода” (типичное значение α=0.05). Обычно число степеней свободы n
вычисляют по формуле n
= (число разрядов) – 1 – (число оцениваемых параметров) Если X
2 > χ
2 крит, то гипотеза H
0 отвергается, в противном случае принимается. В α∙100% случаев (то есть достаточно редко) такой способ проверки H
0 приведет к “ошибке первого рода”: гипотеза H
0 будет отвергнута ошибочно. Пример.
При исследовании 10 серий из 100 семян подсчитывалось число зараженных мухой-зеленоглазкой. Получены данные: O i
=(16, 18, 11, 18, 21, 10, 20, 18, 17, 21); Здесь неизвестен заранее вектор ожидаемых частот. Если данные однородны и получены для биномиального распределения, то неизвестен один параметр доля p
зараженных семян. Заметим, что в исходной таблице фактически имеется не 10 а 20 частот, удовлетворяющих 10 связям: 16+84=100, … 21+79=100.
X 2 = (16-100p) 2 /100p +(84-100(1-p)) 2 /(100(1-p))+…+
(21-100p) 2 /100p +(79-100(1-p)) 2 /(100(1-p))
Объединяя слагаемые в пары (как в примере с монетой), получаем ту форму записи критерия Пирсона, которую обычно пишут сразу: X 2 = (16-100p) 2 /(100p(1-p))+…+ (21-100p) 2 /(100p(1-p)).
Теперь если в качестве метода оценки р использовать минимум расстояния Пирсона, то необходимо найти такое p
, при котором X
2 =min
. (Модель старается по возможности “подстроиться” под данные эксперимента.) Критерий Пирсона - это наиболее универсальный из всех используемых в статистике. Его можно применять к одномерным и многомерным данным, количественным и качественным признакам. Однако именно в силу универсальности следует быть осторожным, чтобы не совершить ошибки. 1.Выбор разрядов.
Оценка параметров
. Использование “самодельных”, неэффективных методов оценки может привести к завышенным значениям расстояния Пирсона. Выбор правильного числа степеней свободы
. Если оценки параметров делаются не по частотам, а непосредственно по данным (например, в качестве оценки среднего берется среднее арифметическое), то точное число степеней свободы n
неизвестно. Известно лишь, что оно удовлетворяет неравенству: (число разрядов – 1 – число оцениваемых параметров) < n
< (число разрядов – 1) Поэтому необходимо сравнить X
2 с критическими значениями χ
2 крит вычисленными во всем этом диапазоне n
. Как интерпретировать неправдоподобно малые значения хи-квадрат?
Следует ли считать монету симметричной, если при 10000 бросаний, она 5000 раз выпала гербом? Ранее многие статистики считали, что H
0 при этом также следует отвергнуть. Теперь предлагается другой подход: принять H
0 , но подвергнуть данные и методику их анализа дополнительной проверке. Есть две возможности: либо слишком малое расстояние Пирсона означает, что увеличение числа параметров модели не сопровождалось должным уменьшением числа степеней свободы, или сами данные были сфальсифицированы (возможно ненамеренно подогнаны под ожидаемый результат). Пример.
Два исследователя А и B
подсчитывали долю рецессивных гомозигот aa
во втором поколении при моногибридном скрещивании AA
* aa
. Согласно законам Менделя эта доля равна 0.25. Каждый исследователь провел по 5 опытов, и в каждом опыте изучалось 100 организмов. Результаты А: 25, 24, 26, 25, 24. Вывод исследователя: закон Менделя справедлив(?). Результаты B
: 29, 21, 23, 30, 19. Вывод исследователя: закон Менделя не справедлив(?). Однако закон Менделя имеет статистическую природу, и количественный анализ результатов меняет выводы на обратные! Объединив пять опытов в один, мы приходим к хи-квадрат распределению с 5 степенями свободы (проверяется простая гипотеза): X 2 A = ((25-25) 2 +(24-25) 2 +(26-25) 2 +(25-25) 2 +(24-25) 2)/(100∙0.25∙0.75)=0.16
X 2 B = ((29-25) 2 +(21-25) 2 +(23-25) 2 +(30-25) 2 +(19-25) 2)/(100∙0.25∙0.75)=5.17
Среднее значение m
[χ
2 n
=5 ]=5, среднеквадратичное отклонение σ[χ
2 n
=5 ]=(2∙5) 1/2 =3.2. Поэтому без обращения к таблицам ясно, что значение X
2 B
типично, а значение X
2 A
неправдоподобно мало. Согласно таблицам P
(χ
2 n
=5 <0.16)<0.0001. Этот пример – адаптированный вариант реального случая, произошедшего в 1930-е годы (см. работу Колмогорова “Об еще одном доказательстве законов Менделя”). Любопытно, что исследователь A
был сторонником генетики, а исследователь B
– ее противником. Путаница в обозначениях.
Следует различать расстояние Пирсона, которое при своем вычислении требует дополнительных соглашений,от математического понятия случайной величины хи-квадрат. Расстояние Пирсона при определенных условиях имеет распределение близкое к хи-квадрат с n
степенями свободы. Поэтому желательно НЕ обозначать расстояние Пирсона символом χ
2 n
, а использовать похожее, но другое обозначение X
2. . Критерий Пирсона не всесилен.
Существует бесконечное множество альтернатив для H
0 , которые он не в состоянии учесть. Пусть вы проверяете гипотезу о том, что признак имел равномерное распределение, у вас имеется 10 разрядов и вектор наблюдаемых частот равен (130,125,121,118,116,115,114,113,111,110). Критерий Пирсона не c
может “заметить” того, что частоты монотонно уменьшаются и H
0 не будет отклонена. Если бы его дополнить критерием серий то да! Распределения
Пирсона (хи – квадрат), Стьюдента и Фишера
С помощью нормального распределения определяются три
распределения, которые в настоящее время часто используются при статистической
обработке данных. В дальнейших разделах книги много раз встречаются эти
распределения. Распределение
Пирсона (хи - квадрат) – распределение случайной
величины где случайные величины X
1
,
X
2
,…,
X n
независимы и имеют одно и тоже
распределение N
(0,1). При этом число слагаемых, т.е. n
, называется «числом степеней
свободы» распределения хи – квадрат. Распределение
хи-квадрат используют при оценивании дисперсии (с помощью доверительного
интервала), при проверке гипотез согласия, однородности, независимости, прежде
всего для качественных (категоризованных) переменных, принимающих конечное число
значений, и во многих других задачах статистического анализа данных . Распределение t
Стьюдента –
это распределение случайной величины где случайные величины U
и X
независимы, U
имеет распределение стандартное
нормальное распределение N
(0,1), а X
– распределение хи – квадрат с
n
степенями свободы. При этом n
называется «числом степеней свободы»
распределения Стьюдента. Распределение
Стьюдента было введено в 1908 г. английским статистиком В. Госсетом, работавшем
на фабрике, выпускающей пиво. Вероятностно-статистические методы использовались
для принятия экономических и технических решений на этой фабрике, поэтому ее
руководство запрещало В. Госсету публиковать научные статьи под своим именем.
Таким способом охранялась коммерческая тайна, «ноу-хау» в виде
вероятностно-статистических методов, разработанных В. Госсетом. Однако он имел
возможность публиковаться под псевдонимом «Стьюдент». История Госсета -
Стьюдента показывает, что еще сто лет назад менеджерам Великобритании была
очевидна большая экономическая эффективность вероятностно-статистических методов. В
настоящее время распределение Стьюдента – одно из наиболее известных
распределений среди используемых при анализе реальных данных. Его применяют при
оценивании математического ожидания, прогнозного значения и других
характеристик с помощью доверительных интервалов, по проверке гипотез о
значениях математических ожиданий, коэффициентов регрессионной зависимости,
гипотез однородности выборок и т.д. . Распределение
Фишера – это распределение случайной величины где случайные величины Х 1
и Х 2
независимы и имеют распределения хи – квадрат с числом
степеней свободы k
1
и k
2
соответственно. При этом пара (k
1
,
k
2
)
– пара «чисел степеней свободы» распределения Фишера,
а именно, k
1
– число степеней свободы числителя, а k
2
– число степеней свободы
знаменателя. Распределение случайной величины F
названо в честь великого английского
статистика Р.Фишера (1890-1962), активно использовавшего его в своих работах. Распределение
Фишера используют при проверке гипотез об адекватности модели в регрессионном
анализе, о равенстве дисперсий и в других задачах прикладной статистики . Выражения
для функций распределения хи - квадрат, Стьюдента и Фишера, их плотностей и
характеристик, а также таблицы, необходимые для их практического использования,
можно найти в специальной литературе (см., например, ). Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL
ХИ2.РАСП()
построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат
(Х 2 , ХИ2,
англ.
Chi
-
squared
distribution
)
применяется в различных методах математической статистики: Определение
: Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1
2 + x 2
2 +…+ x n
2 имеет распределение Х 2
с n степенями свободы. Распределение
Х 2
зависит от одного параметра, который называется степенью свободы
(df
,
degrees
of
freedom
). Например, при построении число степеней свободы
равно df=n-1, где n – размер выборки
. Плотность распределения
Х 2
выражается формулой: Распределение Х 2
имеет несимметричную форму, равно n, равна 2n. В файле примера на листе График
приведены графики плотности распределения
вероятности и интегральной функции распределения
. Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x. Имеет Х 2
-распределение
с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом: Следовательно, выборочное распределение
статистики y, при выборке
из нормального распределения
, имеет Х 2
-распределение
с n-1 степенью свободы. Это свойство нам потребуется при . Т.к. дисперсия
может быть только положительным числом, а Х 2
-распределение
используется для его оценки, то y
д.б. >0, как и указано в определении. В MS EXCEL, начиная с версии 2010, для Х 2
-распределения
имеется специальная функция ХИ2.РАСП()
, английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности
(см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2
-распределение
, примет значение меньше или равное х, P{X <= x}). Примечание
: Т.к. ХИ2-распределение
является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА)
для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА)
или =1-ХИ2.РАСП.ПХ(x;n)
. А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ)
возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ)
, т.е. плотность вероятности
ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП()
, которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП()
и ХИ2.РАСП.ПХ()
перекрывают возможности этой функции. Функция ХИ2РАСП()
оставлена в MS EXCEL 2010 для совместимости. ХИ2.РАСП()
является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения
(третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения
, т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}. Вышеуказанные функции MS EXCEL приведены в . Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x
: P{X <= x}. Это можно сделать несколькими функциями: ХИ2.РАСП(x; n; ИСТИНА) Функция ХИ2.РАСП.ПХ()
возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1. Найдем вероятность, что случайная величина Х примет значение больше заданного x
: P{X > x}. Это можно сделать несколькими функциями: 1-ХИ2.РАСП(x; n; ИСТИНА) Обратная функция используется для вычисления альфа
- , т.е. для вычисления значений x
при заданной вероятности альфа
, причем х
должен удовлетворять выражению P{X <= x}=альфа
. Функция ХИ2.ОБР()
используется для вычисления доверительных интервалов дисперсии нормального распределения
. Функция ХИ2.ОБР.ПХ()
используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР()
вернет такое значение случайной величины х, для которого P{X<=x}=0,05. В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ()
использовалась функция ХИ2ОБР()
. Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат: Некоторые примеры расчетов приведены в файле примера на листе Функции
. Ниже приведено соответствие русских и английских названий функций: Т.к. обычно ХИ2-распределение
используется для целей математической статистики (вычисление доверительных интервалов,
проверки гипотез и др.),
и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится. При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).Применение хи-квадрат критерия для проверки сложных гипотез
Важные моменты
Графики функций

Полезное свойство ХИ2-распределения
Тогда случайная величина y
равная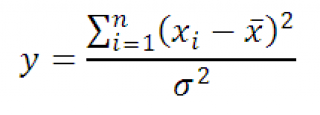
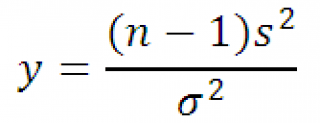
ХИ2-распределение в MS EXCEL
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.Примеры
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Функции MS EXCEL, использующие ХИ2-распределение
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerseОценка параметров распределения
Приближение ХИ2-распределения нормальным распределением

